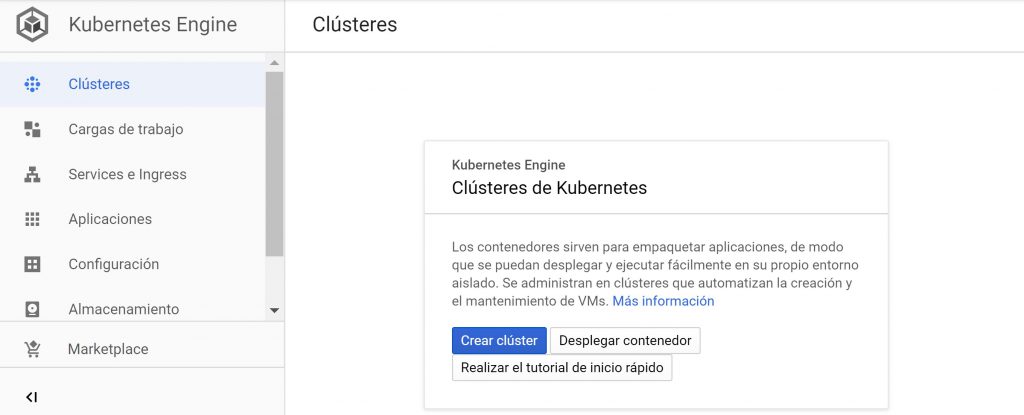
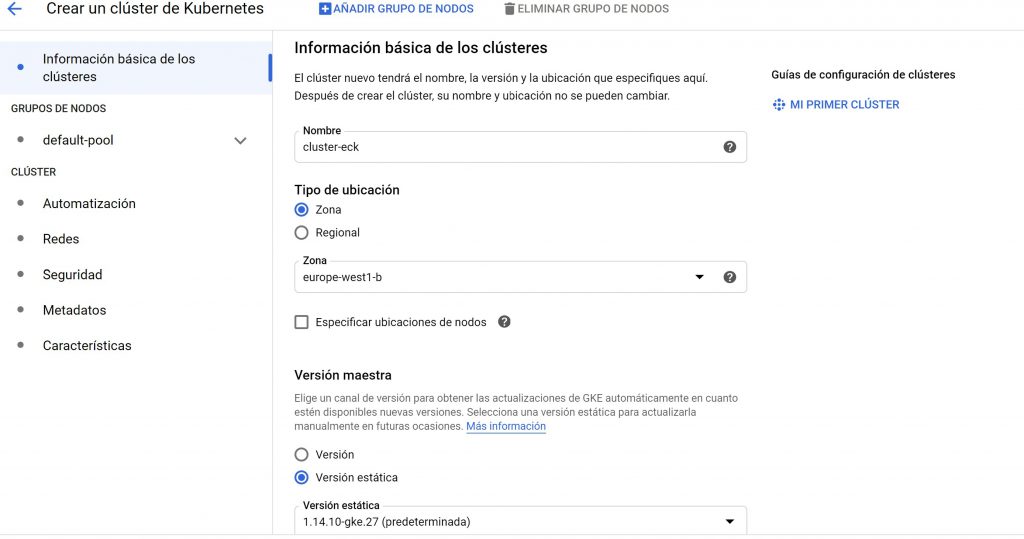
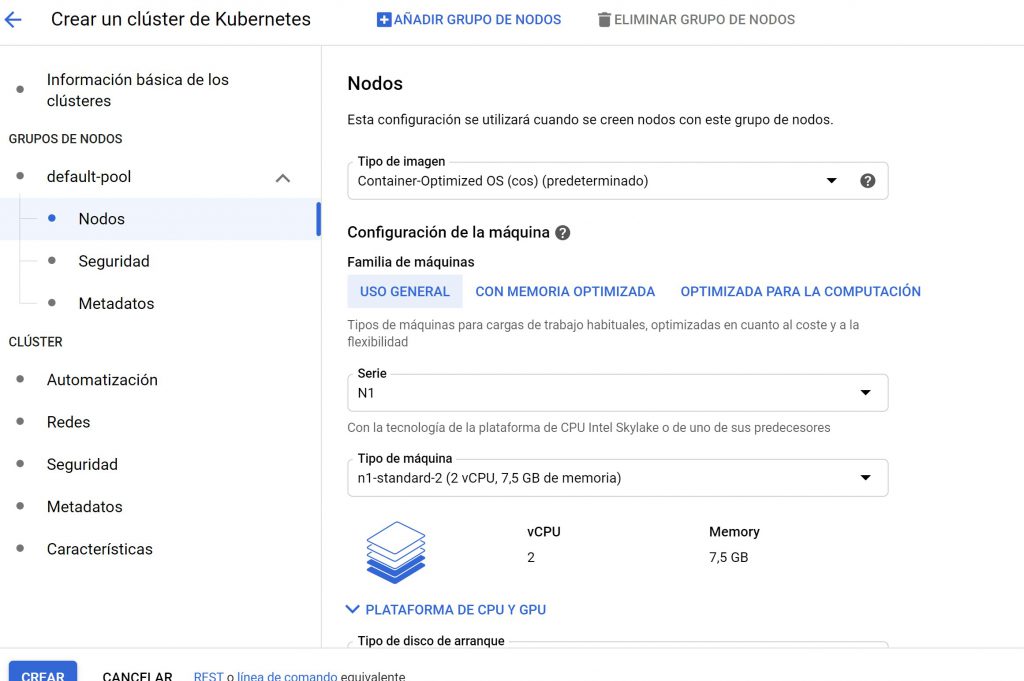
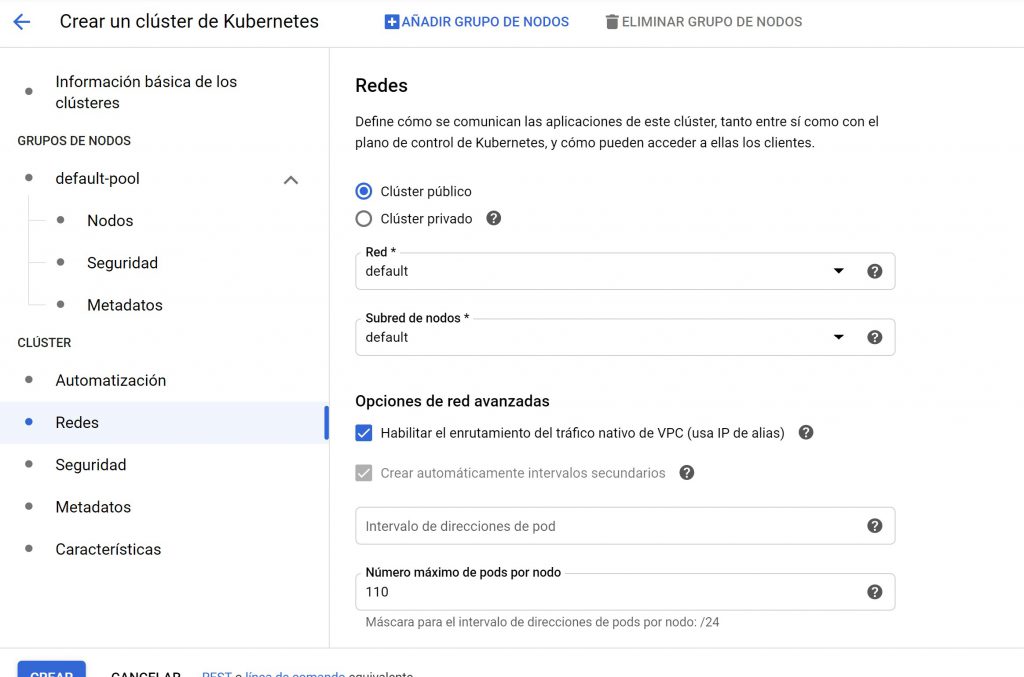
Curso Google Cloud
Con este post comienzo una serie dedicada a Google Cloud y a sus diferentes servicios y recursos. En este caso hablaré de regiones y zonas de disponibilidad en la plataforma Google Cloud.
Ventajas de mover aplicaciones a un proveedor de Cloud
Cuando ejecutamos nuestras aplicaciones en un datacenter on-premise siempre tenemos que planificar con anterioridad la capacidad que los servidores van a poder soportar, si nos equivocamos, tendremos que realizar la compra y provisión de nuevos servidores, lo cuál equivale no sólo a más dinero sino también conlleva tiempo.
En contraposición, en un proveedor de Cloud el pago de los recursos es por uso y éstos son elásticos, de manera que si la carga de nuestro sistema aumenta, podemos adaptar la capacidad del mismo en minutos. Los puntos clave por tanto son los siguientes:
- Coste de la infraestructura variable en función del uso frente al coste que nos supone on-premise (pago por uso).
- Beneficio a partir de la economía de escala, al utilizar la infraestructura de grandes gigantes como son los proveedores de cloud pública.
- Ya no desearemos más capacidad en nuestro sistema, pues tendremos el que sea necesario.
- No necesitamos realizar una inversión para tener nuestro data-center.
- Podemos ejecutar nuestros sistemas y aplicaciones a nivel global en minutos.
Cuando hablamos de Google Cloud tenemos las siguientes ventajas:
- Es uno de los 3 principales proveedores de cloud pública del mundo junto con Amazon Web Services (AWS) y Azure.
- Provee más de 200 servicios en la nube.
- Destaca por su confiabilidad, seguridad y alto-rendimiento ya que es la misma infraestructura que utiliza Google para servir sus aplicaciones a más de mil millones de usuarios: Gmail, YouTube, Google Search, etc.
- Es la nube más limpia, ya que es una nube carbon-neutral. El 100% de la electricidad es generada a través de energía renovable.
¿Porqué necesitamos regiones y zonas?
Imaginemos que tenemos un data-center en Londres que es donde ejecutamos nuestra aplicación, cómo resolveríamos los siguientes puntos:
- Acceso lento desde otras partes del mundo (high latency).
- Qué pasaría si el data center se cae. La aplicación no estaría disponible.
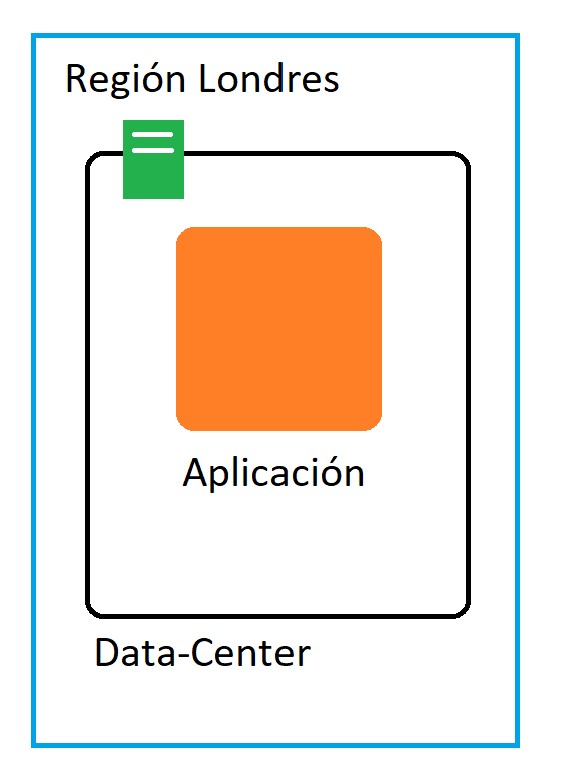
Para solucionar los retos anteriores, podemos añadir otro data-center en la región de Londres y desplegar en él otra instancia de nuestra aplicación. Veamos si resuelve los problemas encontrados:
- (PENDIENTE) Sigue existiendo un acceso lento desde otros puntos del planeta.
- (RESUELTO) Si se cae un data-center la aplicación estaría disponible en el otro datacenter.
- Pero qué ocurre si toda la región de Londres cae? La aplicación no estaría disponible.
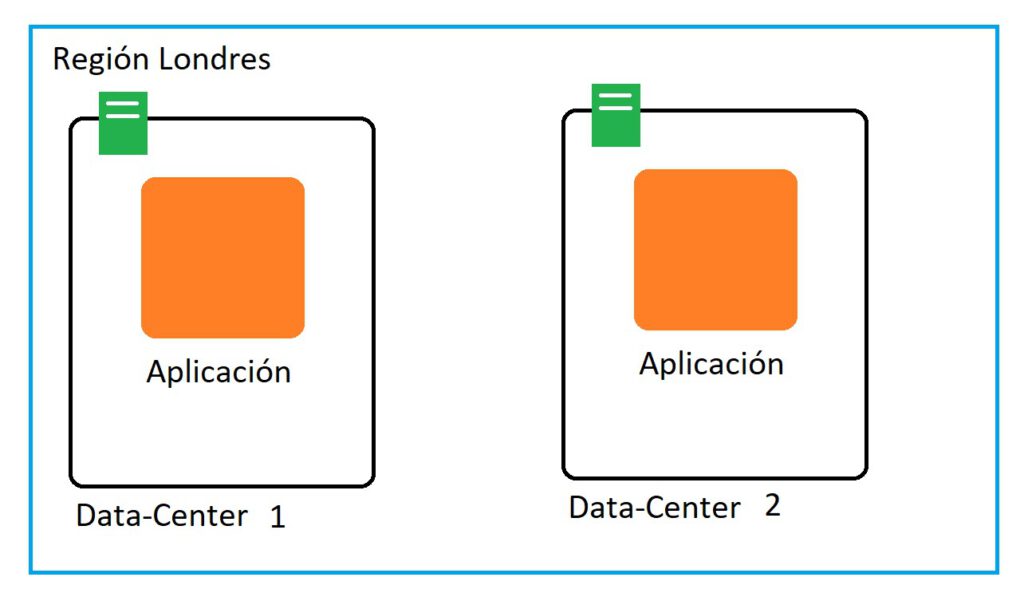
Qué ocurre si añadimos a lo anterior otra región idéntica a la de Londres en Los Ángeles:
- (RESUELTO PARCIALMENTE) Dependiendo de la zona desde la que accedes la aplicación puede ser servida desde la región más cercana para evitar una latencia elevada.
- (RESUELTO) Si un data-center se cae podemos servir la aplicación desde el otro data-center de cada región.
- (RESUELTO) Si una región se cae, la aplicación sigue estando disponible desde la otra región mientras la región se restaura.
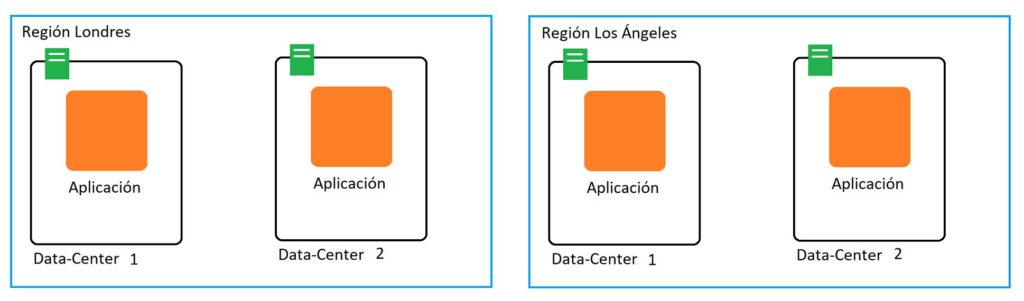
Entendiendo las regiones y zonas de disponibilidad en google cloud
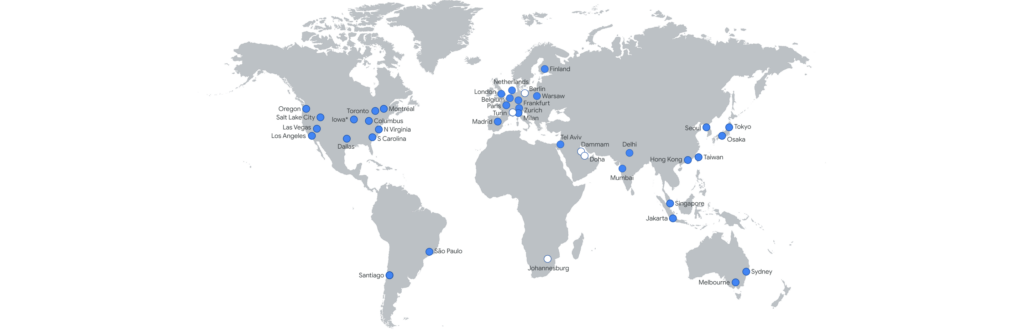
Una REGIÓN es una localización específica de los recursos. Google Cloud provee de más de 20 regiones en todo el mundo y se expanden año a año. Las ventajas de tener un mayor número de regiones:
- Alta-Disponibilidad.
- Baja Latencia. Puedes servir tus aplicaciones desde la región más próxima a tus usuarios.
- Aplicaciones y compañías globales. Una compañía del tamaño que sea puede servir sus productos alrededor de todo el planeta independientemente de dónde se ubique.
- Ser capaz de cumplir con las regulaciones de los distintos gobiernos. Por ejemplo la normativa de tener los datos almacenados dentro de un país específico.
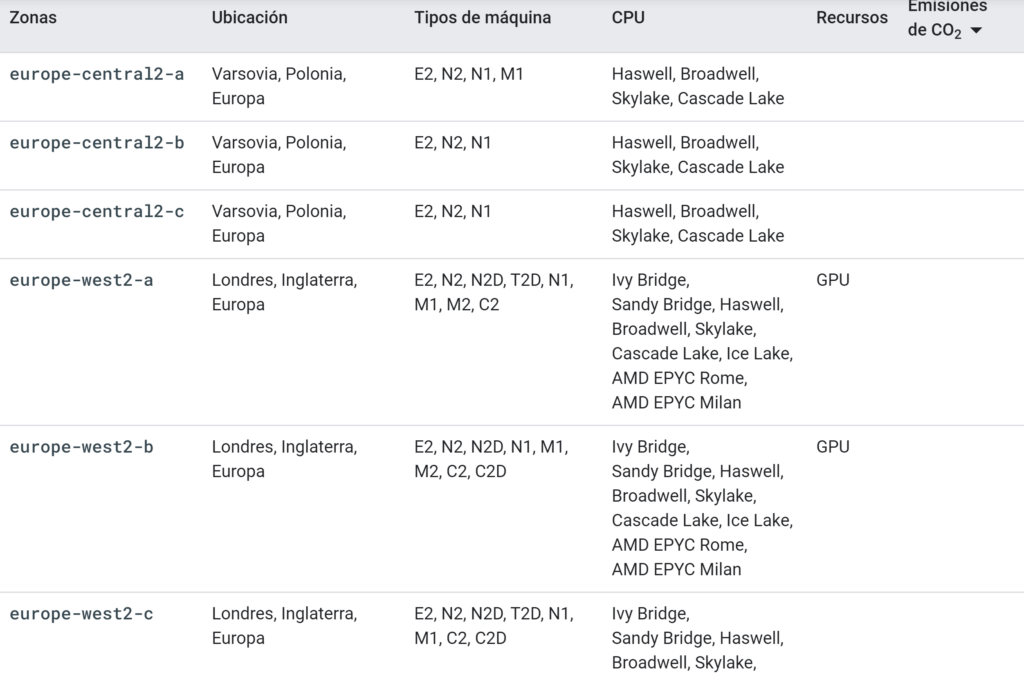
Para obtener alta disponibilidad en las regiones, se incorporan las ZONAS (data-centers dentro de la misma región geográfica). Cada REGIÓN tiene 3 o más ZONAS para incrementar la disponibilidad y la tolerancia a fallos dentro de la región. Las ZONAS tienen enlaces de muy baja latencia entre ellas, pero están los suficientemente separadas para evitar fallos globales.
El nombre de las zonas se corresponde con el nombre de la región, seguido de una letra que las identifica (a, b, c, d…) como puede verse en la siguiente tabla:
En este post hemos visto el concepto de Regiones y Zonas en Google Cloud en futuros artículos veremos los demás servicios de Google Cloud.